Dokumentumkezelés, az RPA sikertényezője

A papírtól és a tolltól elköszönünk – a billentyűzetet és az ERP rendszert bevezetjük.
De mi okozza a kihívást a dokumentumokhoz kapcsolódó munkában?
Európában évente átlagosan 125 kg* papírt használ el mindenki, aminek a 26%-át* írásra használjuk. Az üzleti papírhasználat még mindig 22%-kal* növekszik évente. A környezetvédelmi szempontokat és pénzügyi költségeit nézve egyértelmű, hogy a vállalkozások miért próbálják csökkenteni papírfelhasználásukat, de van egy másik aspektusa is ennek a digitalizációnak: a folyamatok. Ezalatt azt értjük, hogy a legtöbb vállalkozás egyre inkább igyekszik csökkenteni időrabló manuális folyamatait, mint például az egyszerűbb számlázási folyamatokat.
Míg a különféle üzleti folyamatokban több különböző dokumentumot is (szerződések, számlák, levelek stb.) szükséges kezelni, a robotautomatizálás egyik legfontosabb sikertényezője az, hogy miként tudjuk kinyerni és értelmezni az azokban található adatokat, információt.
De mi okozza a kihívást a dokumentumokhoz kapcsolódó munkában?
Strukturális bonyolultságukat illetően 3 típusú dokumentum létezik:
1. A strukturált dokumentumnak van egy fix formátuma, pontosan tudjuk, mi hova kerül a dokumentumon.
2. A félig strukturált dokumentum kevésbé rögzített formátumú, mint az előző, de tudjuk, milyen adatoknak kell tartalmazzon. Erre jó példa a számla - mivel tudjuk, hogy a fizetendő összeget, a számlázási dátumot, a számlázási címet valahol a dokumentumon fel kell tüntetni.
3. A nem strukturált dokumentumok általában szabad szövegesek, mint pl. az e-mail, vagy egy szerződés.
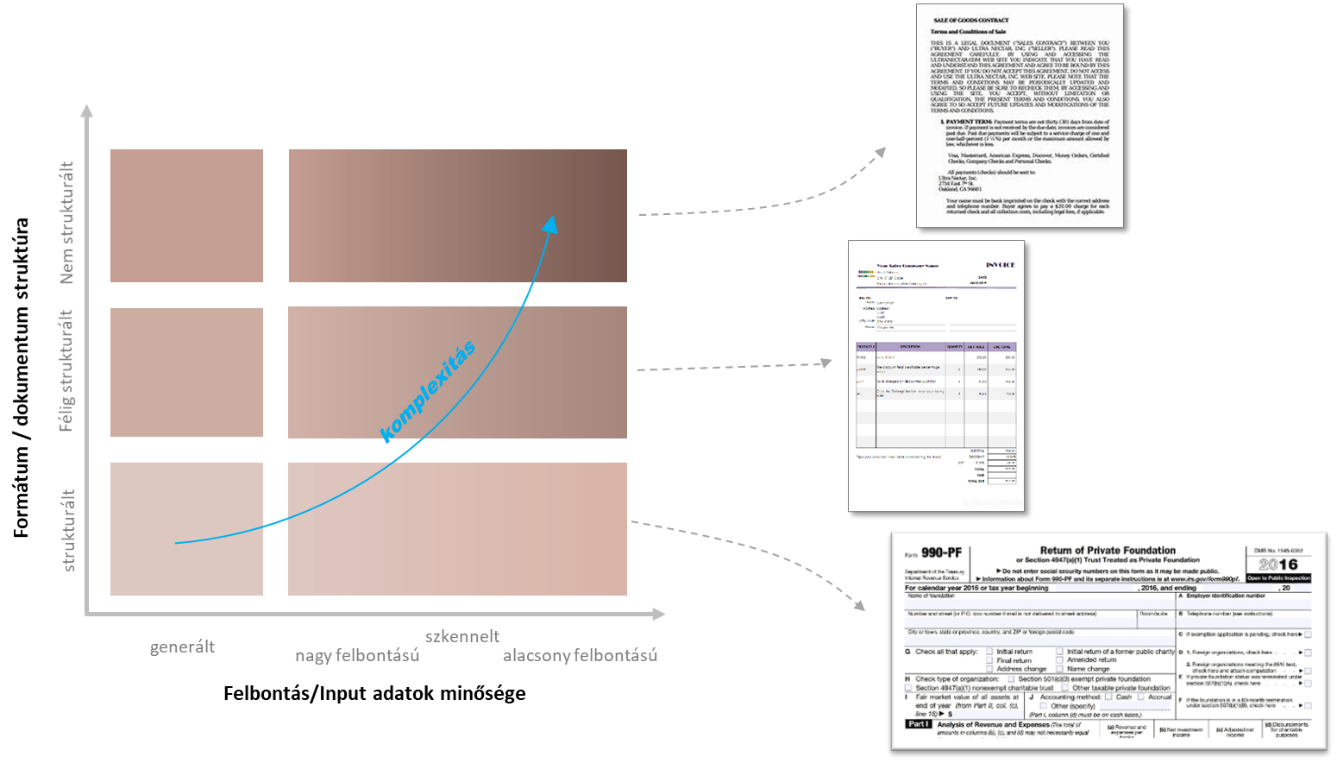
Tehát egyrészről a dokumentum struktúrájának a bonyolultsága határozza meg, hogy mennyire nehéz kinyerni az adatokat, de mit befolyásol a minőség és a felbontás?
Miután a dokumentum megvan a számítógépen, a másik szempont a „digitális” minőség, mely alapján az alábbi főbb csoportokba rendezhetőek:
- A dokumentum digitálisan, nyomtató és szkenner nélkül jött létre.
- A dokumentum szkennelve van, így beolvasásakor nagyobb kihívást jelent az adatok kinyerése, ami nagymértékben függ a beolvasás minőségétől.
Most, hogy tudjuk, hogyan néznek ki a dokumentumok, nézzük, hogyan működik a dokumentumkezelés folyamata.
1. A legelső lépés annak a meghatározása, hogy milyen adatokat kell keresnie a szoftverrobotnak.
2. Ezután digitalizálni kell a bemenetet, hogy megkaphassuk a tartalmat (elsődlegesen szkennelt dokumentumok esetében).
3. A dokumentumokat kategorizálni kell az információk elolvasása előtt.
4. Ezután itt az ideje, hogy kinyerjük a munka elvégzéséhez szükséges adatokat, információt.
5. Miután elvégeztük a fenti lépéseket, az utolsó teendő az adatok felhasználása.
Mint láthatjuk, van egy általános módszertan, amely segít eligazodni, hogy az egyes esetekben milyen technológiát és megközelítést kell alkalmaznunk céljaink elérése érdekében.
Minden ügyfél és minden dokumentumkezelési kihívás különböző, de a fenti logika adja az alapját minden esetben a BCA UiPath alapú dokumentumkezelésének.
Dokumentumkezelési folyamatok automatizálásán gondolkodik, vagy csak jobban érdekli a téma?
Kattintson a lenti gombra, hogy hozzáférjen esettanulmányi előadásunkhoz!
*Források:
The State of the Global Paper Industry (2018) – Environmental Paper Network
Facts About Paper: How Paper Affects the Environment (2019) – Toner Buzz.