Orchestrator API - Második rész

Orchestrator API sorozatunk következő részében a fókusz arra irányul, hogy az API végpontok hogyan használhatóak a telepítés automatizálására, illetve hogyan lehet megkönnyíteni üzemeltetői feladatokat vele.
Az előző blogbejegyzés egy olyan útvonalon indult el, aminek a célja a UiPath Orchestrator API funkcionalitásának felfedezése volt. Eredetileg az Orchestrator API-val foglalkozó blog bejegyzések duológiaként jelentek volna meg (, mint egy trilógia csak két részből állt volna), viszont a legjobb szappanoperák lábnyomaiba lépve (előzmény történetekkel, folytatásokkal, mellékszálakkal és egyebekkel), a téma fennmaradó része két újabb blog bejegyzésre osztódott (eddig) – ezek közül az első lesz a lenti iromány.
Előző alkalommal röviden bevezetésre került, hogy hogyan hívhatók meg ezek az API végpontok, majd a második rész bemutatta, hogy ezek az API végpontok miképpen használhatóak mint alternatív megoldások olyan esetben, ha az eszköz dobozos funkcionalitása nem elegendő.
A következőkben a fókusz arra irányul majd, hogy hogyan használhatók ezek az API végpontok a telepítés automatizálására, illetve hogyan lehet megkönnyíteni üzemeltetői feladatokat vele.
A környezetek közötti telepítés egy manuális, lineáris és repetitív feladat. Általában, a következő történik egy megfelelő szinten szabályozott nagyvállalati architektúrában (ahol 3 különböző környezet van):
1. Az elkészült UiPath kódokat becsomagolja és feltölti az Orchestrátorba a fejlesztő és valamilyen formátumban telepítési dokumentációt szolgáltat. A telepítési dokumentáció tartalmazni fogja, hogy milyen process-ek, asset-ek, queue-k és egyedi csomagok telepítése szükséges.
2. Az üzemeltetői csapat – a telepítési dokumentáció segítségével - feltelepíti a megoldást a teszt környezetre.
3. Telepítési és környezeti tesztek kerülnek elvégzésre à Ha ezek mind sikeresek, akkor válik tesztelhetővé a megoldás a felhasználók számára.
4. Amint a felhasználói tesztek befejeződtek és az élesedési dátum kiválasztásra került akkor éles környezetre telepíthető a megoldás.
A 2. és a 4. lépés automatizálható az Orchestrator API végpontok segítségével. Amennyiben már lyukasztásra került a tűzfal, a feladat kifejezetten egyszerű: gyűjtsünk be minden releváns adatot Orchestrator A-ból és töltsük be Orchestrator B-be. (Amennyiben nincs lehetőség lyukasztásra akkor is megoldható az automatizáció, csak két részre esik a folyamat – ilyes esetben authentkációra sem lesz szükség.) Amennyiben a telepítés automatizációja egy robot folyamattal kerül megvalósításra, akkor csak egy authentikácós hívásra lesz szükség, mivel a robot képes lesz a beépített authentikációra annak az Orchestrátornak az irányában, ahonnan indításra került. Miután az authentikáció megtörtént, minden releváns adat letölthető Orchestrator A-ból (DEV) és felvehető Orchestrator B-be (TEST). Egy folyamat migráció hasonló módon történhet, mint a következő sorban leírtak:
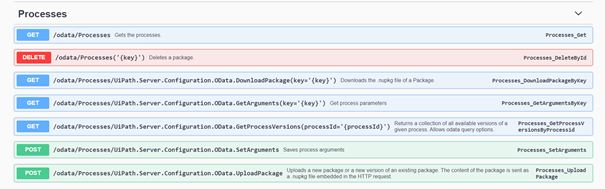
- A DEV környezetben az /odata/Process végpont GET metódussal felhasználható arra, hogy egy adott csomag azonosító kulcsa meghatározható lehessen (a kulcs verzió számok szerint egyedi)
- Majd, amint a kulcs beazonosításra került az /odata/Processes/UiPath.Server.Configuration.OData.GetArguments(key='{key}') végpont GET metódussal letöltésre kerülhet a .nupkg csomag ami tartalmazza a folyamatot.
- Majd a TEST környezeten az /odata/Processes/UiPath.Server.Configuration.OData.UploadPackage végpont POST metódussal arra használható, hogy az DEV környezetből letöltött csomag TEST környezetre feltölthető legyen.
Egy nagyon hasonló minta követhető a process-es ütemezésére szolgáló process schedule-okra (/odata/ProcessSchedules), az asset-ekre (/odata/Assets) illetve a queue-kra (/odata/QueueDefinitions).
Az üzemeltetői feladatok is hasonlóan leképezhetőek. Tömeges felhasználó felvétel, tömeges hozzáférési jog módosítások, tömeges felhasználó aktiválás és deaktiválás, tömeges felhasználó törlés – mind olyan feladatok, amik automatizálásra tudnak kerülni ezeknek az API hívásoknak a segítségével. Például egy egyszerű, tömeges felhasználó létrehozás elérhető a következő módon (amennyiben a felhasználói szerepek és adatok meghatározásra kerülnek egy input file-ban):
1. Az /odata/Roles végpont GET metódussal felhasználható arra, hogy a felhasználó szerepek azonosítói megszerezhetők legyenek.
2. Majd az /odata/Users végpoint POST metódussal felhaszálható arra, hogy felhasználókat lehessen vele létrehozni.
Egy minimális módosítással ez a megoldás a felhasználó frissítésre is képes lenne:
1. Az /odata/Roles végpont GET metódussal felhasználható arra, hogy a felhasználó szerepek azonosítói megszerezhetők legyenek.
2. Az /odata/Users végpont GET metódussal felhasználható arra, hogy a felhasználók azonosítói megszerezhetők legyenek.
3. Miután az adott felhasználó összepárosításra került a talált azonosítóval, akkor ott, ahol csak frissítésre van szükség az odata/Users({key}) végpont PUT metódusával a felhasználható adatai frissíthetőek.
4. Az összes többi felhasználóra a /odata/Users végpont POST metódusa felhasználható arra, hogy felhasználókat hozzunk létre.
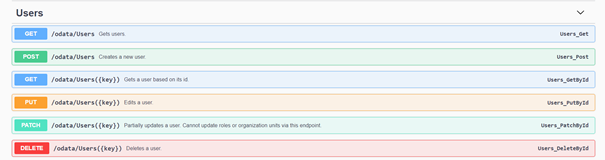
A fent említett többi üzemeltetői feladat is egy nagyon hasonló folyamatot követne. Aktiválhatók vagy deaktiválhatók felhasználók az /odata/Users({key})/UiPath.Server.Configuration.OData.SetActive végpont POST metódusával, vagy akár törölhetők az odata/Users({key}) végpont DELETE metódusával.
Az összes végpont megtalálható az Orchestator swagger oldalán! Nyugodtan feltételezhetjük, hogy majdnem az összes, ha nem az összes funkcionalitás, ami elérhető számunkra a GUI-n keresztül elérhető számunkra a felsorolt API-k valamelyikén keresztül.