Orchestrator API - Első rész

Az Orchestrator az automatizáció szíve. Hogyan hívható meg egy orchestrator API, és hogyan használhatók ezek az API -k a folyamatok javítására? Orchestrator API blogbejegyzésünk első része a fenti kérdésekre válaszol.
Sokan szórakoztatónak találják bizonyos rajok (hal vagy madár rajok) mozgását: az állatok mozdulatai szépen koreografált táncokra emlékeztethetik az embert – gyönyörű látvány. Amíg ezek az élőlények ösztöneikre hagyatkoznak mozzanatiakban, az emberek számára a csapat-munka, illetve a csapat-organizáció általában vezetőt követel.
Ebben az értelemben, a digitális munkaerő sem különbözik a sajátunktól: koordinációra van szüksége a hatékony működéshez. Az Orchestrator – a UiPath automatizációs eszközének egy alkatrésze – az a csapatvezető komponens, ami ezt az irányítást biztosítja.
Mostani blog bejegyzésünk az Orchestátorról fog szót ejteni, illetve azon belül arról, hogy hogyan használhatók az Orchestator API endpoint-jai. Az írás azt feltételezi, hogy az olvasó rendelkezik a legtöbb „általános” Orchestatorral kapcsolatos, illetve munkasorral (queue) kapcsolatos háttértudással (https://docs.uipath.com/orchestrator). A téma két részre került bontásra és a következő kérdésekre szeretne választ adni:
1. Hogyan lehet meghívni egy Orchestrator API-t – általában?
2. Hogyan használhatjuk ezeket az API-kat, hogy javítsunk az automatizált folyamatainkon?
3. Hogyan használhatjuk ezeket az API-kat, hogy automatizáljuk a folyamatok telepítését, illetve segítsük az operációt?
4. Hogyan használhatjuk ezeket az API-kat, hogy integrálni tudjunk más rendszereket az Orchestrátorral?
Az első két kérdésre próbálunk választ keresni ebben a részben.
Az összes elérhető Orchestrator API endpoint megtalálható az alkalmazás swagger oldalán. A legkönnyebben úgy tudunk elnavigálni erre az oldalra, ha az URL végére beírjuk azt, hogy „/swagger” (pl: https://{orchestatorURL}/swagger). A UiPath.WebAPI az OData protocolt használja (RESTful API), így 2 hívásra van szükségünk egy feladat elvégzéséhez:
1. Az első hívás az authentikációra szolgál, ami egy bearer token-t fog számunkra visszaadni (az Orchestrator felhasználói adatainkra lesz csupán szükségünk)
2. A második hívás – ami tartalmazni fogja az előbb megszerzett tokent, ami authentikálja a hívást – fogja elvégezni számunkra a feladatot.
Az OData protocol most nem kerül kifejtésre, mivel túlmutat a jelenlegi írás méretén, viszont elérhető egy pontos dokumentáció azok számára, akiket ez érdekel (angol nyelvű).
Ezeket az API végpontokat meg lehet pingelni a swagger felhasználói felületéről, viszont bármely más erre alkalmas eszközt is lehet használni: SoapUI-t, Postman-t stb.
A Postman egy jó választás, mivel a UiPath a teljes ezzel kapcsolatos könyvtárát elérhetővé tette mindenki számára, ahol működő példákat találhatunk (https://www.postman.com/uipath/workspace/uipath-s-public-workspace/collection/15161494-5acd865c-9266-4ef1-b497-1bed9c93c811?ctx=documentation).
Ezeket az API végpontokat egy futtatórobottal is meg tudjuk hívni az Orchestrator HTTP Request activity használatával. Ennek a bemeneteli paraméterei egy szerializált JSON érték (string) és az egyik végpont a Orchestrator swagger oldaláról. Az authentikációt maga az activity végzi (a hívás annak a futtatórobotnak a nevében authentikál amelyikkel a folyamatot futtatjuk) – így ez egy nagyon egyszerű módja egy UiPath.WebApi meghívásának. A listában felsorolt API-k közül bármelyiket meg lehet hívni, viszont érdemes figyelni, hogy a futtatórobot felhasználója számára megfelelő szintű jogosultságok kerüljenek kiosztásra, hogy képes legyen meghívni ezeket a végpontokat.
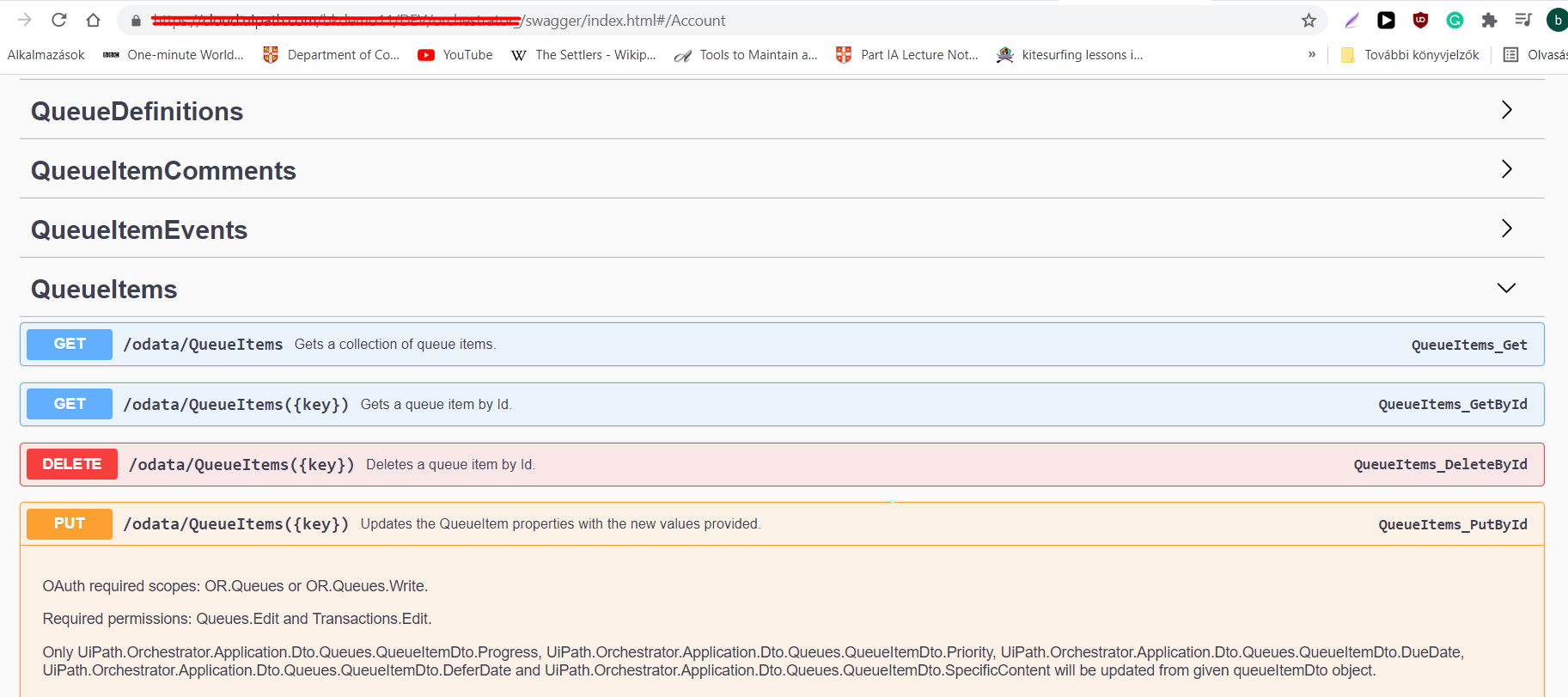
Ha már a fent leírt módon képesek vagyunk meghívni Orchestrator API-kat, a figyelmünket a második kérdésre fordíthatjuk. A legtöbb nagyvállalati RPA megoldás logikája tranzakciós vagy iteratív. Munkasorokat (queue) használunk a folyamatban: az elvégzendő feladatokból egy listát képzünk és a robot (vagy akár több robot amennyiben több feldolgozó robottal dolgozunk) egyesével elvégzi(k) ezeket a feladatokat (egymás után, iteratív módon).
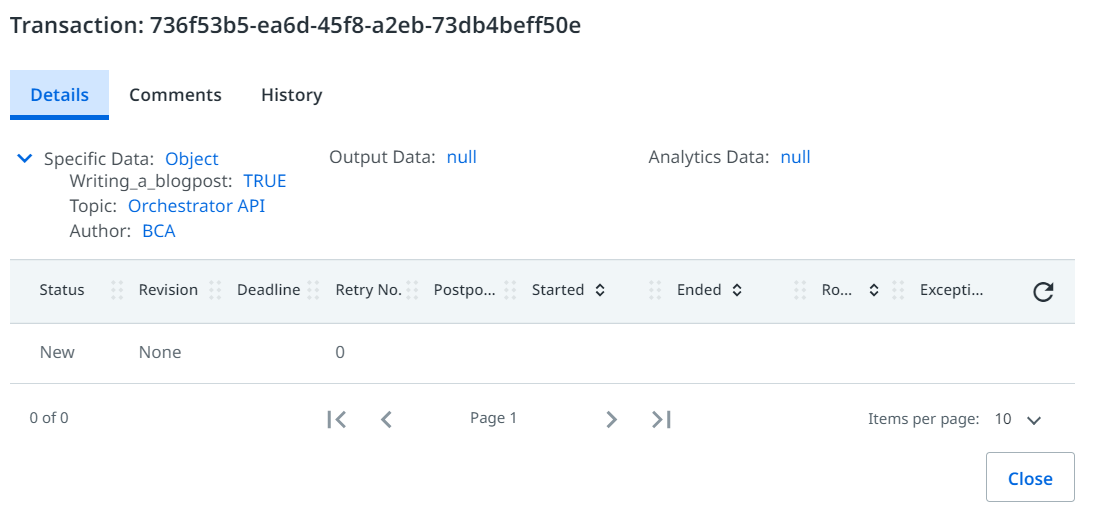
Egy munkaelem (queueitem) ’specific data’ konténere tartalmazza általában az összes bemeneteli/input információt és az elem frissül amint a robot befejezte a feldolgozását. Így, a munkasorok és munkaelemek használhatók riportálásra (hasonlóan, mint ahogyan a UiPath Insight eszköz működik). Ezért hasznos, ha akkora kontrolunk van a munkaelemek felett amekkora csak lehetséges.
Az általános funkcionalitás az esetek jelentős részében elegendő:
- Amennyiben sikeresen feldolgozásra kerül egy munkaelem, akkor képesek vagyunk összegyűjtött információt visszatölteni a munkaelem két adattárolójába (output data & analytics data),
- a munkaelem feldolgozási állapota (progress) örökítésre kerül, ha a munkasor automatikusan újra próbálja a munkaelemet (19.10 verzió óta)
- a munkaelem feldolgozási állapota (progress) örökítésre kerül, ha halasztunk (postpone) egy munkaelemet (19.10 verzió óta)
- amennyiben egy munkaelem feldolgozása sikertelen, képesek vagyunk információt biztosítani arról, hogy miért volt sikertelen a feldolgozás (a ’Reason’ és a ’Details’ mezőkben).
Viszont vannak olyan speciális esetek amikor az általános funkcionalitás nem elégséges:
- Van, hogy szeretnénk a futás során összegyűjtött információt sikertelen feldolgozás esetén is visszaszolgáltatni (vagy egy egész csokornyi információt). Tudnánk használni a fent említett ’Reason’ & ’Details’ mezőt, viszont ez kifejezetten nehézkes lenne. Ami fontosabb az viszont az, hogy a szolgáltatott információ formátuma eltérne a sikeresen feldolgozott munkaelemekétől (ami megnehezíti a riportálást).
- Van, hogy szeretnénk indokot megjelölni a halasztásra, hogy ez is riportálásra kerülhessen.
- Végül pedig, vannak olyan helyezetek, ahol szükséges az input információ módosítása, hogy később is feldolgozható legyen a munkaelem (fontos megjegyezni, hogy ez általában nem ajánlott).
A /odata/QueueItems({munkasor elem kulcs}) végponttal képesek vagyunk frissíteni a munkaelemet ahogyan szeretnénk (egy sikertelen munkaelemhez tárolhatunk információt ugyanabban az adattároló-konténerben ahol a sikeres munkaelemek információi kerülnek tárolásra, indokot tudunk megjelölni a halasztásra, tudjuk módosítani az input adatot stb.), ami mindig egy pozitívum.
A második részben meg fogjuk vizsgálni, hogy hogyan tudjuk a Webhook-okat használva integrálni az Orchestrátorunkat más rendszerekhez, illetve azt, hogy hogyan tudjuk automatizálni a folyamataink élesítését és egyéb operációs feladatokat ezeknek az API végpontoknak a segítségével.