Orchestrator API - Part 1.

Orchestrator is the heart of automation. How can an orchestrator API be called and how can these APIs be used to enhance processes? Part 1 of our Orchestrator API blog post covers the above questions.
One may find watching a school of fish (or a flock of birds) profoundly entertaining: the movement of these bodies is reminiscent of well-choreographed dances – it is a spectacular sight. While fish and birds rely much on their instincts for anything they do, group-work or group-organisation (for humans) tends to require leadership.
In this sense, a digital workforce is no different to our own: it requires guidance to function efficiently. Orchestrator – as a component of UiPath’s automation tool - is the team leader, that provides this much needed leadership.
In this blog post, the discussion will be around Orchestrator and more specifically how Orchestrator’s API endpoints can be used. Most “standard” Orchestrator related knowledge and queue related knowledge will be assumed (https://docs.uipath.com/orchestrator). The topic will be split over two posts, and it will attempt to answer the following questions:
1. How can an Orchestrator APIs be called - in general?
2. How can these APIs be used to enhance processes?
3. How can these APIs be used to automate deployment and ease operation?
4. How can these APIs be used to integrate Orchestrator with other systems?
The first two questions will be covered in this post.
A list of all available Orchestrator API endpoints can be found by navigating to its swagger page. The easiest way to navigate to this page would be by writing “/swagger” at the end of Orchestrator’s URL (e.g: https://{orchestatorURL}/swagger). UiPath.WebAPI is based on the OData protocol (RESTful API), thus two calls are needed to perform any task:
1. A first call to authenticate, and to retrieve a bearer token. (One will need only their Orchestrator credentials for this).
2. A second one – containing the token, which authenticates the call - to perform the desired task.
OData will not be elaborated on, as it is outside of the scope of this blogpost, however there is a thorough documentation for all who are interested.
These APIs can be pinged from the swagger UI, but one may call these APIs with any suitable tool: SoapUi, Postman etc.
The latter would be a good choice since UiPath has provided a full Postman library with worked examples (https://www.postman.com/uipath/workspace/uipath-s-public-workspace/collection/15161494-5acd865c-9266-4ef1-b497-1bed9c93c811?ctx=documentation).
These APIs can also be called with a robot using the Orchestrator HTTP Request activity. The parameters are a serialised JSON payload (string) and one of the endpoints listed on the swagger site. Authentication is handled by the activity itself (the call authenticates in the name of the robot that the process is being executed on) - it is a fairly simple way of calling a UiPath.WebAPI. Any of the listed APIs can be called: one should only be mindful to grant sufficient access rights to the robot’s user to allow it to make these calls.
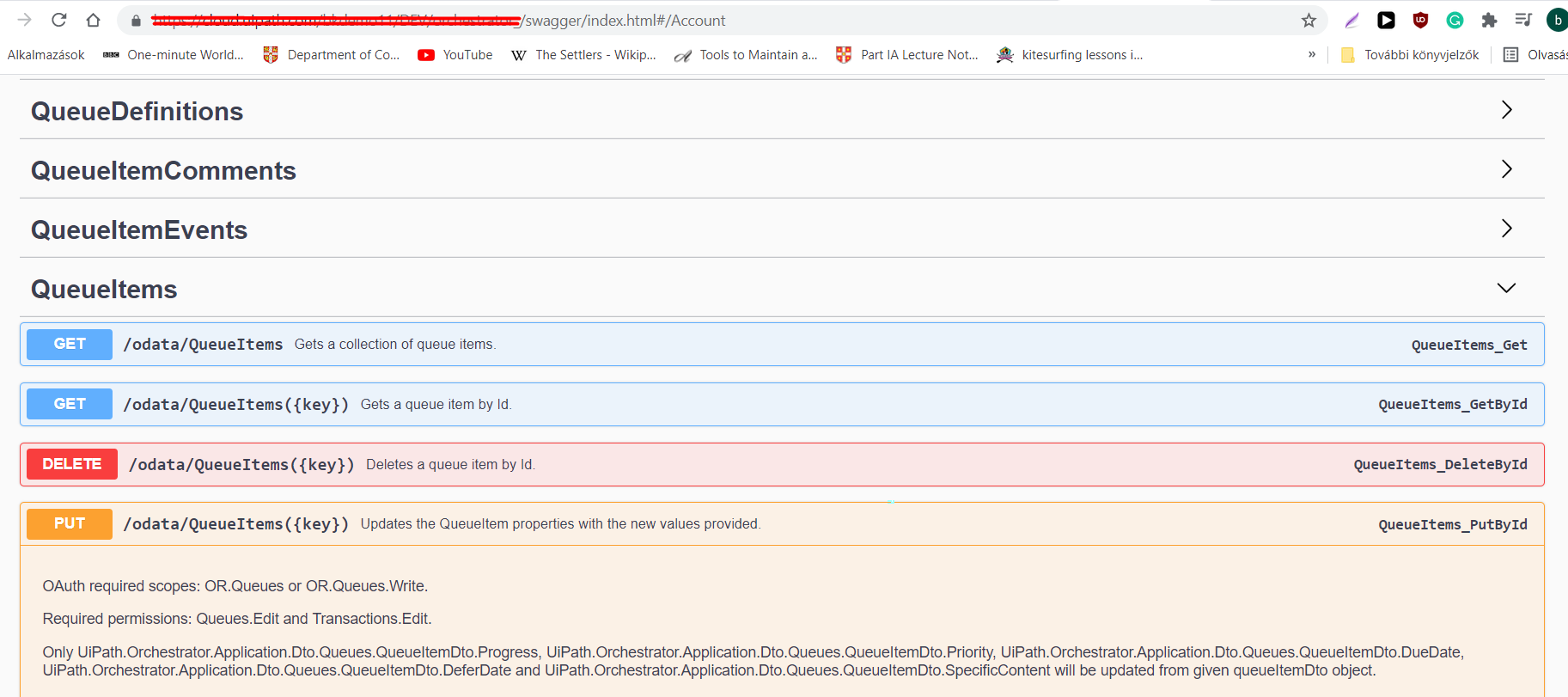
Now that one is able to call these APIs with a robot, our attention can turn to the second question. Most enterprise RPA solutions follow a transactional or iterative design. Queues are used in the process: a list of work items are created, and the robot (or robots if there were multiple dispatchers) work their way through these items (one-by-one in an iterative fashion).
The QueueItem’s Specific Data container usually contains all the relevant input information and the QueueItem updates once the robot has finished processing it. Thus, Queues and QueueItems can be used for reporting (similarly to how UiPath Insights works). Hence it is useful to have as much control over QueueItems as possible.
The standard functionality is often enough for almost everything:
- If an item is successful, we can provide additional data that was gathered during processing in the output data and analytics data containers,
- the progress is inherited if the item is retried (since 19.10),
- the progress is inherited if the item is postponed (since 19.10),
- if an item has failed, one can provide information about why the item has failed in the ‘Reason’ and the ‘Details’ fields.
However, there are specific scenarios where the standard functionality is insufficient:
- Sometimes one may wish to provide output data for further analysis even if the item has failed (or an array of information for items that have failed). Admittedly, we could utilise the ‘Reason’ and the ‘Details’ fields, but it is quite cumbersome. More importantly the format will be different to successful items (which could complicate reporting).
- One may wish to provide a reason for postponing the item, so that it can be reported.
- Finally, there are instances where one may wish to modify the input information stored in the Specific Data container, so that processing is possible at a later date (please note that this is not usually recommended).
Using the /odata/QueueItems({key}) endpoint one can update a QueueItem as they see fit (failed QueueItems could have information stored in the Analytics Data container, a reason for postponing could be provided, specific data can be modified etc.), which is always desirable.
The second part will explore how one could use Webhooks to integrate Orchestrator with other systems and how one could automate deployment and maintenance tasks using these API endpoints.